Finding vulnerabilities in .NET is something I quite enjoy, it generally meets my criteria of only looking for logic bugs. Probably the first research I did was into .NET serialization where I got some interesting results, and my first Blackhat USA
presentation slot. One of the places where you could abuse serialization was in .NET remoting, which is a technology similar to Java RMI or CORBA to access .NET objects remotely (or on the same machine using IPC). Microsoft consider it a legacy technology and you shouldn't use it, but that won't stop people.
One day I came to the realisation that while I'd
talked about how dangerous it was I'd never released any public PoC for exploiting it. So I decided to start writing a simple tool to exploit vulnerable servers, that was my first mistake. As I wanted to fully understand remoting to write the best tool possible I decided to open my copy of Reflector, that was my second mistake. I then looked at the code, sadly that was my last mistake.
TL;DR you can just grab the
tool and play. If you want a few of the sordid details of
CVE-2014-1806 and
CVE-2014-4149 then read on.
.NET Remoting Overview
Before I can describe what the bug is I need to describe how .NET remoting works a little bit. Remoting was built into the .NET framework from the very beginning. It supports a pluggable architecture where you can replace many of the pieces, but I'm just going to concentrate on the basic implementation and what's important from the perspective of the bug. MSDN has plenty of resources which go into a bit more depth and there's always the official documentation
MS-NRTP and
MS-NRBF. A good description is available
here.
The basics of .NET remoting is you have a server class which is derived from the
MarshalByRefObject class. This indicates to the .NET framework that this object can be called remotely. The server code can publish this server object using the remoting APIs such as
RemotingConfiguration.RegisterWellKnownServiceType. On the client side a call can be made to APIs such as Activator.GetObject which will establish a transparent proxy for the Client. When the Client makes a call on this proxy the method information and parameters is packaged up into an object which implements the
IMethodCallMessage interface. This object is sent to the server which processes the message, calls the real method and returns the return value (or exception) inside an object which implements the
IMethodReturnMessage interface.
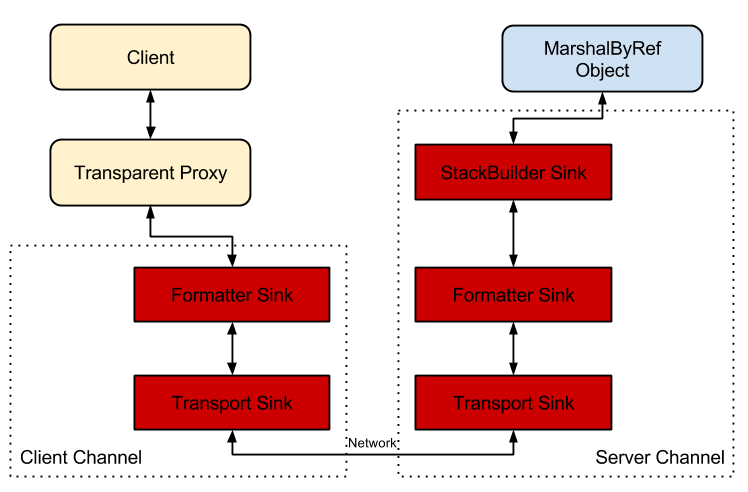
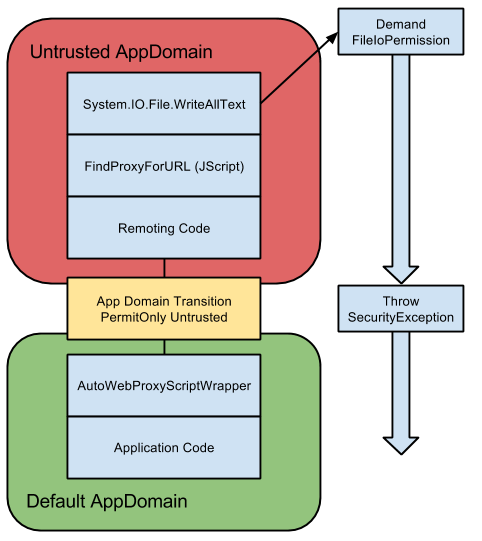
When a remoting session is constructed we need to create a couple of Channels, a Client Channel for the client and a Server Channel for the server. Each channel contains a number of pluggable components called sinks. A simple example is shown below:
The transport sinks are unimportant for the vulnerability. These sinks are used to actually transport the data in some form, for example as binary over TCP. The important things to concentrate on from the perspective of the vulnerabilities are the
Formatter Sinks and the
StackBuilder Sink.
Formatter Sinks take the
IMethodCallMessage or
IMethodReturnMessage objects and format their contents so that I can be sent across the transport. It's also responsible for unpacking the result at the other side. As the operations are asymmetric from the channel perspective there are two different formatter sinks,
IClientChannelSink and
IServerChannelSink.
While you can select your own formatter sink the framework will almost always give you a formatter based on the
BinaryFormatter object which as we know can be pretty dangerous due to the potential for deserialization bugs. The client sink is implemented in
BinaryClientFormatterSink and the server sink is
BinaryServerFormatterSink.
The StackBuilder sink is an internal only class implemented by the framework for the server. It's job is to unpack the
IMethodCallMessage information, find the destination server object to call, verify the security of the call, calling the server and finally packaging up the return value into the
IMethodReturnMessage object.
This is a very high level overview, but we'll see how this all interacts soon.
The Exploit
Okay so on to the actual vulnerability itself, let's take a look at how the
BinaryServerFormatterSink processes the initial .NET remoting request from the client in the
ProcessMessage method:
IMessage requestMsg;
if (this.TypeFilterLevel != TypeFilterLevel.Full)
{
set = new PermissionSet(PermissionState.None);
set.SetPermission(
new SecurityPermission(SecurityPermissionFlag.SerializationFormatter));
}
try
{
if (set != null)
{
set.PermitOnly();
}
requestMsg = CoreChannel.DeserializeBinaryRequestMessage(uRI, requestStream,
_strictBinding, TypeFilterLevel);
}
finally
{
if (set != null)
{
CodeAccessPermission.RevertPermitOnly();
}
}
We can see in this code that the request data from the transport is thrown into the DeserializeBinaryRequestMessage. The code around it is related to the serialization type filter level which I'll describe later. So what's the method doing?
internal static IMessage DeserializeBinaryRequestMessage(string objectUri,
Stream inputStream, bool bStrictBinding, TypeFilterLevel securityLevel)
{
BinaryFormatter formatter = CreateBinaryFormatter(false, bStrictBinding);
formatter.FilterLevel = securityLevel;
UriHeaderHandler handler = new UriHeaderHandler(objectUri);
return (IMessage) formatter.UnsafeDeserialize(inputStream,
new HeaderHandler(handler.HeaderHandler));
}
For all intents and purposes it isn't doing a lot. It's passing the request stream to a
BinaryFormatter and returning the result. The result is cast to an
IMessage interface and the object is passed on for further processing. Eventually it ends up passing the message to the StackBuilder sink, which verifies the method being called is valid then executes it. Any result is passed back to the client.
So now for the bug, it turns out that nothing checked that the result of the deserialization was a local object. Could we instead insert a remote
IMethodCallMessage object into the serialized stream? It turns out yes we can. Serializing an object which implements the interface but also derived from
MarshalByRefObject serializes an instance of an
ObjRef class which points back to the client.
But why would this be useful? Well it turns out there's a Time-of-Check Time-of-Use vulnerability if an attacker could return different results for the
MethodBase property. By returning a
MethodBase for
Object.ToString (which is always allowed) as some points it will trick the server into dispatching the call. Now once the
StackBuilder sink goes to dispatch the method we replace it with something more dangerous, say
Process.Start instead. And you've just got arbitrary code to execute in the remoting service.
In order to actually exploit this you pretty much need to implement most of the remoting code manually, fortunately it is documented so that doesn't take very long. You can repurpose the existing .NET
BinaryFormatter code to do most of the other work for you. I'd recommand taking a look at the github project for more information on how this all works.
So that was CVE-2014-1806, but what about CVE-2014-4149? Well it's the same bug, MS didn't fix the TOCTOU issue, instead they added a call to
RemotingServices.IsTransparentProxy just after the deserialization. Unfortunately that isn't the only way you can get a remote object from deserialization. .NET supports quite extensive COM Interop and as luck would have it all the
IMessage interfaces are COM accessible. So instead of a remoting object we instead inject a COM implementation of the IMethodCallMessage interface (which ironically can be written in .NET anyway). This works best locally as they you don't need to worry so much about COM authentication but it should work remotely. The final fix was to check if the object returned is an instance of
MarshalByRefObject, as it turns out that the transparent COM object,
System.__ComObject is derived from that class as well as transparent proxies.
Of course if the service is running with a
TypeFilterLevel set to
Full then even with these fixes the service can still be vulnerable. In this case you can deserialize anything you like in the initial remoting request to the server. Then using reflecting object tricks you can capture
FileInfo or
DirectoryInfo objects which give access to the filesystem at the privileges of the server. The reason you can do this is these objects are both serializable and derive from
MarshalByRefObject. So you can send them to the server serialized, but when the server tries to reflect them back to the client it ends up staying in the server as a remote object.
Real-World Example
Okay let's see this in action in a real world application. I bought a computer a few years back which had pre-installed the Intel Rapid Storage Technology drivers version 11.0.0.1032 (the specific version can be downloaded
here). This contains a vulnerable .NET remoting server which we can exploit locally to get local system privileges. A
note before I continue, from what I can tell the latest versions of these drivers no longer uses .NET remoting for the communication between the user client and the server so I've never contacted Intel about the issue. That said there's no automatic update process so if, like me you had the original insecure version installed well you have a trivial local privilege escalation on your machine :-(
Bringing up Reflector and opening the
IAStorDataMgrSvc.exe application (which is the local service) we can find the server side of the remoting code below:
public void Start()
{
BinaryServerFormatterSinkProvider serverSinkProvider
new BinaryServerFormatterSinkProvider {
TypeFilterLevel = TypeFilterLevel.Full
};
BinaryClientFormatterSinkProvider clientSinkProvider = new BinaryClientFormatterSinkProvider();
IdentityReferenceCollection groups = new IdentityReferenceCollection();
IDictionary properties = new Hashtable();
properties["portName"] = "ServerChannel";
properties["includeVersions"] = "false";
mChannel = new IpcChannel(properties, clientSinkProvider, serverSinkProvider);
ChannelServices.RegisterChannel(mChannel, true);
mServerRemotingRef = RemotingServices.Marshal(mServer,
"Server.rem", typeof(IServer));
mEngine.Start();
}
So there's a few thing to note about this code, it is using
IpcChannel so it's going over named pipes (reasonable for a local service). It's setting the
portName to
ServerChannel, this is the name of the named pipe on the local system. It then registers the channel with the secure flag set to True and finally it configures an object with the known name of
Server.rem which will be exposed on the channel. Also worth nothing it is setting the
TypeFilterLevel to
Full, we'll get back to that in a minute.
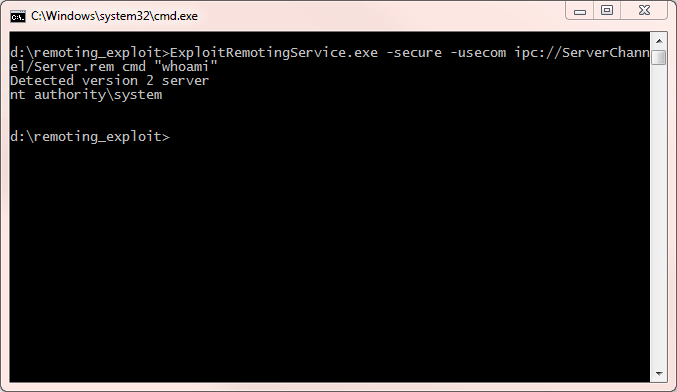
For exploitation purposes therefore we can build the service URL as
ipc://ServerChannel/Server.rem. So let's try sending it a command. In this case I had updated for the fix to CVE-2014-1806 but not for CVE-2014-4149 so we need to pass the
-usecom flag to use a COM return channel.
Well that was easy, direct code execution at local system privileges. But of course if we now update to the latest version it will stop working again. Fortunately though I highlighted that they were setting the
TypeFilterLevel to
Full. This means we can still attack it using arbitrary deserialization. So let's try and do that instead:
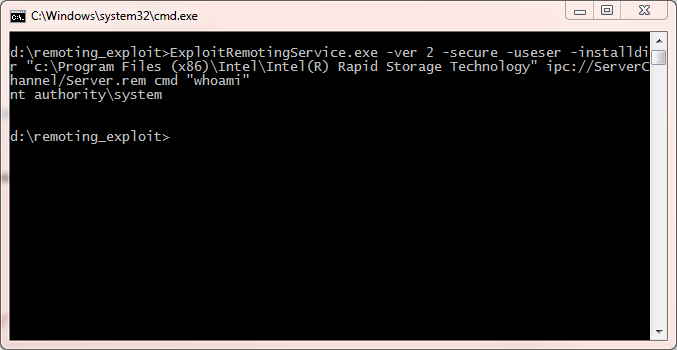
In this case we know the service's directory and can upload our custom remoting server to the same directory the server executes from. This allows us to get full access to the system. Of course if we don't know where the server is we can still use the
-useser flag to list and modify the file system (with the privileges of the server) so it might still be possible to exploit even if we don't know where the server is running from.
Mitigating Against Attacks
I can't be 100% certain there aren't other ways of exploiting this sort of bug, at the least I can't rule out bypassing the TypeFilterLevel stuff through one trick or another. Still there are definitely a few ways of mitigating it. One is to not use remoting, MS has deprecated the technology for WCF, but it isn't getting rid of it yet.
If you have to use remoting you could use secure mode with user account checking. Also if you have complete control over the environment you could randomise the service name per-deployment which would at least prevent mass exploitation. An outbound firewall would also come in handy to block outgoing back channels.








.png)